Formular Tools im Vergleich
3. August 2025
7 Minuten zum lesen
7 Min.
Office Stuttgart
Bitfactory Solutions GmbH
Gutenbergstr. 77a
70197 Stuttgart
Germany

3. August 2025
7 Minuten zum lesen
7 Min.

7. Juli 2025
4 Minuten zum lesen
4 Min.
Wie Sie den Vorteil von Machine Learning nutzen und damit effektivere Unternehmensprozesse erstellen, erfahren Sie in diesem Blog Artikel.
Als Teilbereich der Künstlichen Intelligenz spielt Machine Learning (ML) eine bedeutende Rolle bei der Verarbeitung von Daten. Viele Unternehmen können von ML-Technologien profitieren, da sie ihnen helfen, wichtige Erkenntnisse aus großen Datenmengen zu extrahieren. ML-Systeme haben den Vorteil, dass sie Datensätze entscheidend schneller und präziser analysieren und verarbeiten können als Menschen.
Machine Learning (ML) oder auf Deutsch Maschinelles Lernen ist ein Teilbereich der Künstlichen Intelligenz. Die ML-Algorithmen erkennen Muster in Datensätzen und sind in der Lage, auf Basis der gewonnenen Erkenntnisse eigenständig Lösungen zu entwickeln. Durch das Sammeln von Erfahrungen eignen sie sich künstliches Wissen an.
Machine Learning oder Maschinelles Lernen ist die Wissenschaft und Anwendung von Algorithmen, die Daten verstehen und daraus konkrete Aufgaben erfüllen können.
Damit das System die richtigen Ergebnisse liefert, müssen Menschen vorher relevante Daten und Algorithmen bereitstellen sowie Regeln für die Analyse festlegen. Die richtige Vorbereitung der Daten ist entscheidend für die Ergebnisqualität der ML-Systeme.

Jedes ML-Projekt basiert auf Daten, mit denen das System arbeiten und bestimmte Anforderungen umsetzen soll. Zu Beginn eines Projektes müssen wir klären, welche Informationen sich in den Daten befinden, welchen Mehrwert diese bieten und ob eine Umsetzung des Vorhabens auf Grundlage dieser Daten möglich ist. Hier kommt die explorative Datenanalyse zum Einsatz.
Die explorative Datenanalyse bezieht sich auf den Prozess der Durchführung der ersten Untersuchungen der Daten. Dadurch entdeckt sie Muster, findet Anomalien, testet Hypothesen und überprüft Annahmen mit Hilfe von zusammenfassenden Statistiken und grafischen Darstellungen.
Bevor das Projekt starten kann, ist es von Vorteil, die Daten zuerst zu verstehen und zu versuchen, möglichst viele Erkenntnisse daraus zu gewinnen. Um diesen Prozess genauer zu spezifizieren, dient eine Checkliste mit Fragestellungen als Orientierung während der explorativen Datenanalyse:
Konnten wir alle Fragen beantworten und die jeweiligen Erkenntnisse daraus ziehen, ist die explorative Datenanalyse beendet.
Zur Veranschaulichung schauen wir uns die Beantwortung der Fragen am Beispiel der Predictive Maintenance an. Dabei handelt es sich um eine vorausschauende Wartung, bei der mit Hilfe der zur Verfügung stehenden Sensoren versucht wird, Störungen an Maschinen vorherzusehen, bevor diese überhaupt auftreten.
Im realen Anwendungsfall werden die jeweiligen Schritte genauer ausgeführt sowie explizite Methoden genannt. Zum allgemeinen Verständnis reicht diese Darstellung jedoch aus.
Ein großer Teil der explorativen Datenanalyse befasst sich bereits mit der Vorverarbeitung der Daten. Insbesondere die Fragestellungen drei bis fünf, beziehen sich darauf.
Die Qualität der Daten und die Menge der nützlichen Informationen sind die Schlüsselfaktoren für den Erfolg eines Machine Learning Algorithmus. Deshalb ist es zwingend notwendig, die Daten zuerst anzupassen, bevor jegliche Anwendung von Verfahren mit Maschinellem Lernen sinnvoll ist.
In diesem Schritt sollen die Erkenntnisse der Analyse dazu dienen, die Daten für einen Machine Learning Algorithmus vorzubereiten. Im Optimalfall verbessert sich damit die Qualität des Resultats, das die Maschinen liefern. So können sie die gewünschten Anforderungen besser erfüllen.
Teilweise sind bestimmte Daten auch erst durch eine gezielte Vorverarbeitung für das Machine Learning nutzbar. Nehmen wir als Beispiel eine Zuordnungsaufgabe, in der wir verschiedene Zeitungsartikel einer Kategorie zuweisen. Kategorien könnten Sport, Politik, Wirtschaft oder Ähnliches sein. Machine-Learning-Algorithmen arbeiten ausschließlich mit Zahlenwerten. Die Artikel stellen jedoch Texte dar, sodass zuerst eine sinnvolle Konvertierung der Texte in eine Zahlenfolge (Vektor) erfolgen muss. Ansonsten kann keine Zuordnung stattfinden. Diese Zuordnung kann anschließend für Empfehlungssysteme verwendet werden, in denen Benutzer anhand ihrer Interessen die richtigen Artikel angezeigt bekommen.
Bei einer Objekterkennung in Bildern sieht die Vorverarbeitung dagegen ganz anders aus. Die Objekterkennung hat das Ziel, bestimmte Dinge auf einem Bild zu lokalisieren und diese dabei zu erkennen. Damit werden Bilder durchsuchbar. Da Bilder eine hohe Auflösung vorweisen können, ist es sinnvoll, diese Auflösung zu reduzieren (Interpolation). Damit wird die Dimensionalität reduziert, sodass schneller Modelle trainiert und Vorhersagen getroffen werden können. Auch das Konvertieren von Farb- in Graustufenbilder kann eine wirksame Methode sein, um die Dimensionalität zu reduzieren.
Die Vorverarbeitung ist damit individuell für die jeweils vorliegenden Daten und den Anwendungsfall auszuwählen.
Möchten Sie selbst ein Machine Learning Projekt umsetzen? Mit unserem Expertenwissen und unserer Erfahrung unterstützen wir Sie gerne dabei! Erfahren Sie mehr über unseren KI-Service oder kontaktieren Sie uns.
Allein aus den vorverarbeiteten Daten lassen sich noch keine Erkenntnisse gewinnen. Die Machine Learning Systeme sollen die bestehenden Anforderungen mit den zur Verfügung stehenden Daten umsetzen.
Einige Beispiele für Aufgaben, die ML erfüllen kann:
Maschinelles Lernen lässt sich in verschiedene Typen kategorisieren, die im Folgenden kurz erläutert werden:
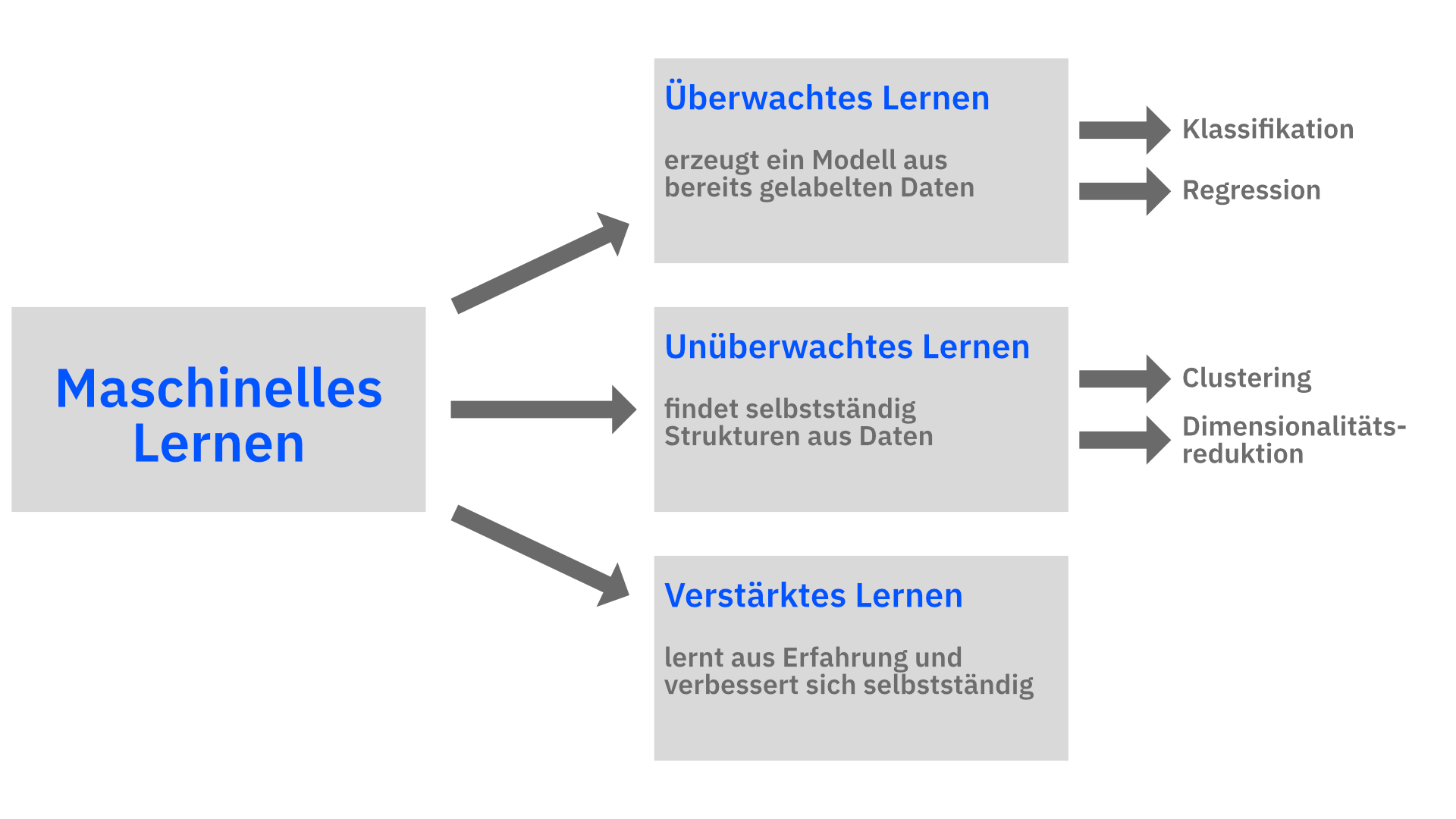 Übersicht über die unterschiedlichen ML-Typen
Übersicht über die unterschiedlichen ML-TypenDas Hauptziel beim überwachten Lernen ist es, ein Modell aus bereits gelabelten Daten zu erzeugen. Dieses erlaubt es, Vorhersagen über weitere unbekannte Daten zu machen. Gelabelt bedeutet in diesem Zusammenhang, dass die Trainingsdaten bereits einer Klasse zugeordnet sind. Der ausgewählte Machine Learning Algorithmus versucht nun, die zur Verfügung stehenden Merkmale aus den Daten zu abstrahieren. Dadurch kann er unbekannte Datensätze anhand ihrer Merkmale wiederum einer Klasse zuordnen.
Zwei Aufgabentypen, die in die Abteilung des überwachten Lernens fallen, sind die Klassifikation und die Regression.
Das Beispiel der Predictive Maintenance können wir in den Bereich der Klassifikation einordnen. Hierbei versuchen wir anhand der Datenströme eine Vorhersage über zukünftige Störungen zu treffen. Liegen also bestimmte sensorische Daten vor, so soll der ML-Algorithmus als Ergebnis Störung oder keine Störung ausgeben.
Ebenso können wir das Verfahren auch als Regression umsetzen. Dabei gibt der ML-Algorithmus als Ergebnis beispielsweise eine kontinuierliche Zahl zwischen 0 und 1 aus, wobei 0 keine Störung und 1 Störung bedeutet. Damit sagt er den prozentualen Anteil einer möglichen Störung vorher und trifft keine diskrete Aussage.
Die Zuordnung von Zeitungsartikeln und die Objekterkennung gliedern sich ebenfalls in die Klassifikation beziehungsweise Regression ein.Die Voraussetzung für die alle Varianten ist, dass Trainingsdaten zur Verfügung stehen.
Im Gegensatz zum überwachten Lernen sind hier beim Trainieren eines Modells keine Labels vorhanden. Es ist also unbekannt, welche Daten welcher Klasse zugehörig sind. Das unüberwachte Lernen versucht nun selbstständig Strukturen in den Daten zu finden, um so relevante Informationen aus den Daten zu extrahieren. Mit diesen Merkmalen können nun weitere Aufgaben angegangen werden.
Teilaufgaben des unüberwachten Lernens sind beispielsweise das Clustering und die Dimensionalitätsreduktion.
Als reale Clustering-Aufgabe können Sie sich die Gruppierung von Kunden eines Unternehmens vorstellen. Damit können Unternehmen automatisiert Personas erstellen, anhand derer sie individuelle Marketing-Strategien anwenden können. Der Vorteil dieser Variante ist, dass keine Beispieldaten vorhanden sein müssen, die wir zuvor manuell einer Kundengruppe zuordnen müssen. Dies geschieht hier automatisiert.
Die letzte Kategorie von Machine Learning ist das verstärkte Lernen. Das Ziel dieses Bereiches ist es, ein System (Agent) zu entwickeln, dass sich selbstständig verbessert. Basierend auf den Interaktionen mit der Umgebung lernt es und passt sein Verhalten an. Der Agent führt also gewisse Aktionen aus, bekommt dafür ein positive oder eine negative Rückmeldung und verändert sein Verhalten dementsprechend. Er versucht dabei die positiven Rückmeldungen zu maximieren.
Ein Beispiel hierfür wäre ein Schachcomputer. Immer wenn der Agent ein Zug ausführt, wird er dafür belohnt, wenn er Figuren des Gegners aus dem Spiel bringt oder das Spiel gewinnt. Verliert er selbst eine Figur oder das Spiel, wird er bestraft. Durch die Erfahrungen entwickelt der Agent sich selbstständig weiter und verbessert sich. Er versucht damit die Reihenfolge an Aktionen zu lernen, die die Summe der Belohnungen maximiert.
Je nach Anforderungen können wir verschiedenen ML-Algorithmen anwenden. Allerdings haben wir noch nicht geklärt, inwiefern die resultierenden Ergebnisse des trainierten Modells gut oder schlecht sind. Um solch eine Aussage zu bekommen und basierend auf dieser das Machine Learning Modell anzupassen, ist eine Model-Evaluation nötig.
Bei der Model-Evaluation wird versucht, die Leistung der Machine Learning Modelle anhand verschiedener Metriken zu bewerten. Daraus sollen die Probleme und mögliche Verbesserungen an dem Algorithmus identifiziert werden, damit diese anschließend angegangen werden können.
So müssen wir beispielsweise bei der Predictive Maintenance überprüfen, ob eine Fehlerkategorisierung zuverlässig funktioniert. Bei der Gruppierung von Kunden schauen wir, ob die Zuordnung sinnig ist. Nur mit Hilfe solch einer Evaluation können wir die Qualität unserer Machine Learning Lösung überprüfen, aufzeichnen und verbessern.
Maschinelles Lernen sowie auch andere Bereiche der Künstlichen Intelligenz können Prozesse in Unternehmen vereinfachen. Sie ermöglichen es, gesammelte Daten richtig zu nutzen, indem sie wichtige Erkenntnisse daraus gewinnen und diese anwenden können. Je besser die Daten vorbereitet und an den Machine Learning Algorithmus angepasst sind, desto besser ist das Ergebnis, das er liefert.
Sie sind interessiert an Projekten mit Künstlicher Intelligenz oder speziell Machine Learning? Wir entwickeln Ihre individuelle KI-Lösung! Kontaktieren Sie uns telefonisch +49 711 21723730 oder per Mail hello@bitfactory.io.

3. August 2025
7 Minuten zum lesen
7 Min.
7. Juli 2025
4 Minuten zum lesen
4 Min.
Werden Sie Teil unserer Mailing Liste und bleiben Sie informiert über Tech, Apps, Backend